什么是内部链接?
内部链接是指向(目标)与该链接位于(源)上的域相同的域的超链接。用外行的术语来说,内部链接是指向同一网站上另一页面的链接。
代码样例
最佳格式
在锚文本中使用描述性关键字可以使您感觉主题或源页面尝试定位的关键字。
什么是内部链接?
内部链接是从域上的一页到同一域上的另一页的链接。它们通常用于主导航中。
这些类型的链接之所以有用,有以下三个原因:
- 它们允许用户浏览网站。
- 他们帮助建立给定网站的信息层次结构。
- 它们有助于在网站上传播链接权益(排名能力)。
SEO最佳实践
内部链接对于建立站点架构和扩展链接公平性(URL也是必不可少的)最有用。出于这个原因,本节是关于使用内部链接构建SEO友好的网站体系结构。
在单个页面上,搜索引擎需要查看内容才能在其庞大的基于关键字的索引中列出页面。他们还需要访问可爬行链接结构(该结构允许蜘蛛程序浏览网站的路径)才能找到网站上的所有页面。(要了解您网站的链接结构是什么样子,请尝试通过Link Explorer运行您的网站。)成千上万个网站犯了严重的错误,即以搜索引擎无法访问的方式隐藏或掩埋其主链接导航。这阻碍了他们获得在搜索引擎索引中列出的页面的能力。下面是如何发生此问题的说明:

在上面的示例中,Google的彩色蜘蛛已到达页面“ A”,并看到到页面“ B”和“ E”的内部链接。无论重要的页面C和D可能到达该站点,蜘蛛都无法访问它们,甚至无法知道它们的存在,因为没有直接的可爬行链接指向这些页面。就Google而言,这些页面基本上不存在-如果知识兔蜘蛛一开始无法到达这些页面,那么内容丰富,关键字针对性强和智能营销根本没有任何区别。
网站的最佳结构看起来类似于金字塔(顶部的大点是首页):
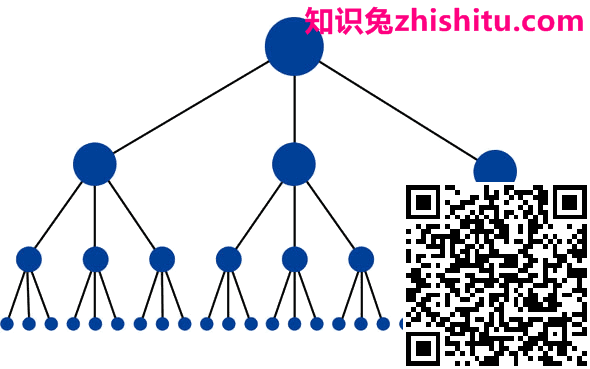
此结构在首页和任何给定页面之间的链接可能最少。这很有用,因为它允许链接权益(排名能力)遍及整个站点,知识兔从而增加了每个页面的排名潜力。这种结构以类别和子类别系统的形式在许多高性能网站(例如Amazon.com)上很常见。
但是,这是如何完成的?最好的方法是使用内部链接和补充URL结构。例如,它们内部链接到位于http://www.example.com/mammals …的页面,其锚文本为“ cats”。以下是格式正确的内部链接的格式。想象一下,该链接位于域名jonwye.com上。

在上面的图示中,“ a”标签表示链接的开始。链接标签可以包含图像,文本或其他对象,所有这些都在页面上分享了一个“可单击”区域,用户可以使用该区域来移动到另一个页面。这是Internet的原始概念:“超链接”。链接引用位置告诉浏览器以及搜索引擎链接指向的位置。在此示例中,URL http://www.jonwye.com被引用。接下来,访问者链接的可见部分在SEO世界中称为“ 锚文本 ”,描述了链接所指向的页面。在此示例中,指向的页面是关于一个叫乔恩·怀(Jon Wye)的人制作的定制皮带的,因此该链接使用锚文本“乔恩·怀的定制设计皮带”。的 标签会关闭链接,因此页面稍后的元素将不会应用链接属性。
这是链接的最基本格式,并且知识兔对于搜索引擎而言非常容易理解。搜索引擎蜘蛛知道他们应该将此链接添加到Web的链接图中,知识兔使用它来计算与查询无关的变量(例如 MozRank),然后知识兔按照它为引用页面的内容建立索引。
以下是页面无法访问并因此无法建立索引的一些常见原因。
提交所需表格中的链接
表单可以包含基本元素(如下拉菜单)或复杂元素(如问卷调查)。在任何一种情况下,搜索蜘蛛都不会尝试访问“提交”表单,因此,引擎无法看到通过表单可访问的任何内容或链接。
只能通过内部搜索框访问的链接
蜘蛛不会尝试执行搜索来查找内容,因此,据估计,数百万个页面隐藏在完全无法访问的内部搜索框后面。
无法解析的Javascript中的链接
使用Javascript构建的链接可能无法抓取,也可能在权重上降低,具体取决于它们的实现方式。因此,知识兔建议在搜索引擎引荐流量非常重要的任何页面上,知识兔使用标准HTML链接代替基于Javascript的链接。
Flash,Java或其他插件中的链接
搜索引擎通常无法访问Flash,Java Applet和其他插件中嵌入的任何链接。
指向由Meta Robots标记或Robots.txt阻止的页面的链接
该元机器人标签和robots.txt的文件都允许网站所有者限制到一个页面访问蜘蛛。
页面上具有数百或数千个链接的链接
所有搜索引擎的爬行限制均为每页150个链接,然后知识兔它们才能停止搜寻与原始页面链接的其他页面。此限制在一定程度上是灵活的,特别重要的页面可能会跟随200个甚至250个以上的链接,但是在通常情况下,明智的做法是将任何给定页面上的链接数限制为150个,否则可能会失去抓取其他页面的能力。
框架或I框架中的链接
从技术上讲,框架和I框架中的链接都是可爬行的,但是从组织和跟踪方面来看,这两个问题都对引擎造成了结构性问题。只有对搜索引擎如何索引和跟踪框架中的链接具有良好技术了解的高级用户才可以将这些元素与内部链接结合使用。
通过避免这些陷阱,网站管理员可以拥有干净的,可抓取的HTML链接,这些链接将使抓取程序轻松访问其内容页面。链接可以应用其他属性,但是引擎会忽略几乎所有这些属性,但rel=”nofollow”标记是重要的例外。
是否想快速浏览您网站的索引?使用Moz Pro之类的工具,链接Explorer或Screaming Frog运行网站爬行。然后知识兔,将抓取打开的页面数与您在Google上运行site:search时列出的页面数进行比较。
Rel =“ nofollow”可以与以下语法一起使用:
取消关注此链接在此示例中,通过将rel=”nofollow”属性添加到链接标记,网站管理员告诉搜索引擎他们不希望将此链接解释为正常的,通过果汁的“编辑投票”。Nofollow的出现是一种帮助阻止自动博客评论,留言簿和链接注入垃圾邮件的方法,但随着时间的流逝,它逐渐演变成一种告诉引擎对通常传递的链接值进行权重限制的方法。每个引擎对标签为nofollow的链接的解释稍有不同。
[ppwp passwords="zhishitu.cn"]
下载体验
下载链接:
如果知识兔链接失效了,请找客服哈
[/ppwp]
发表回复