Paper2GUI,开源AI黑科技工具箱合集,免安装开箱即用
目录
写在前面
近几年,有一类工具出镜率特别高,就是基于各种开源算法、大厂接口衍生出来的 AI 工具。
从语音合成,到老照片人像修复,知识兔从图片、视频高清无损放大、到算法帮你抠图,亦或是转变成动漫人物……
这些本该是高高在上、门槛颇高的 AI 项目,被热心大佬们做成了人人可用的、有图形窗口的傻瓜式软件应用,使得我们可以尝鲜,难道还有比这更让人激动的事情嘛?

Paper2GUI,开源AI黑科技工具箱合集,免安装即开即用
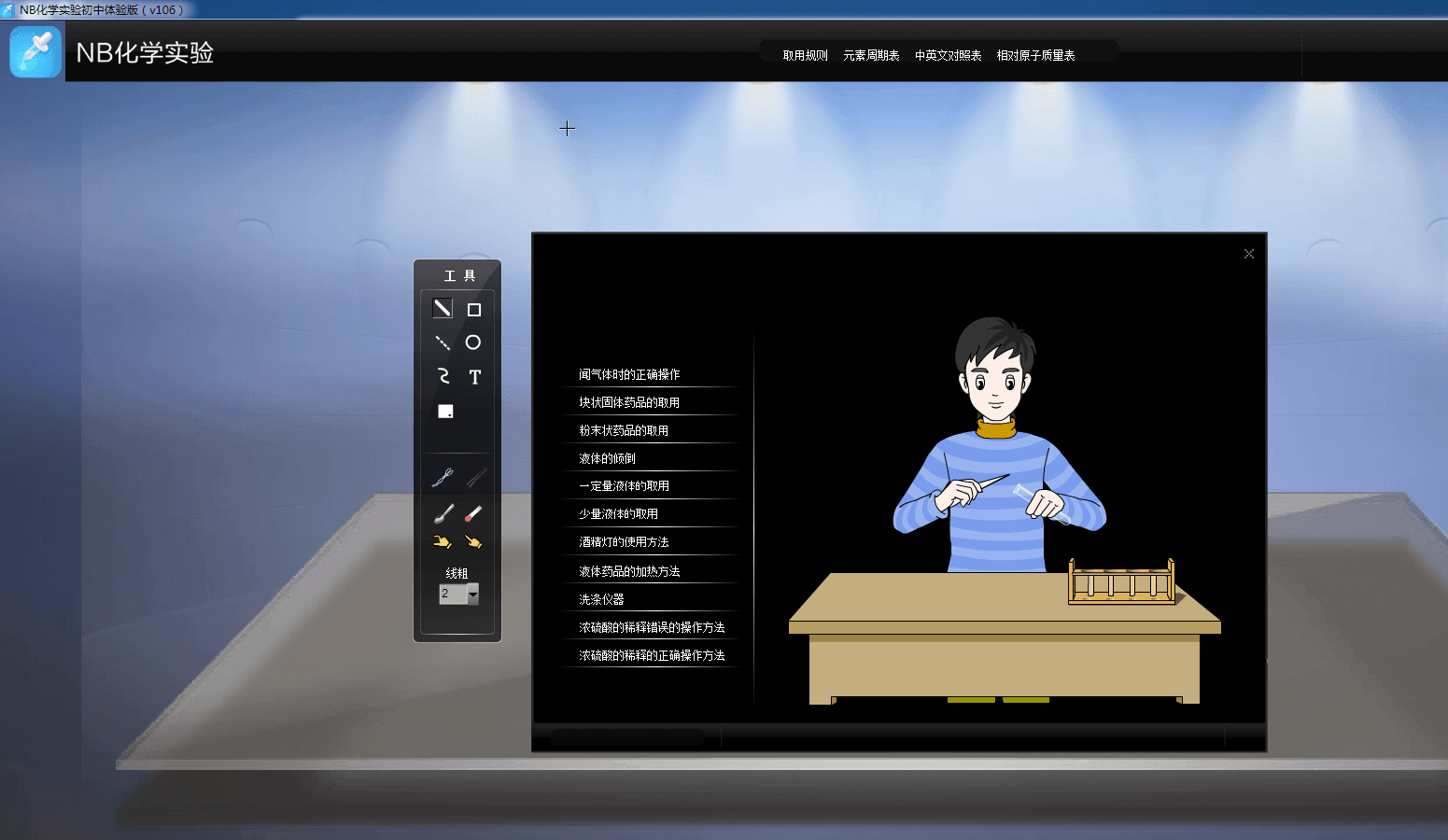
Paper2GUI: 一款面向普通人的AI桌面APP工具箱,免安装即开即用,已支持18+AI模型,内容涵盖语音合成、视频补帧、视频超分、目标检测、图片风格化、OCR识别等领域。
目前开发者分享了绿色免安装的独立运行包,也发布了融合所有功能的安装包,知识兔可以按需使用。效果怎么样,一一来介绍。
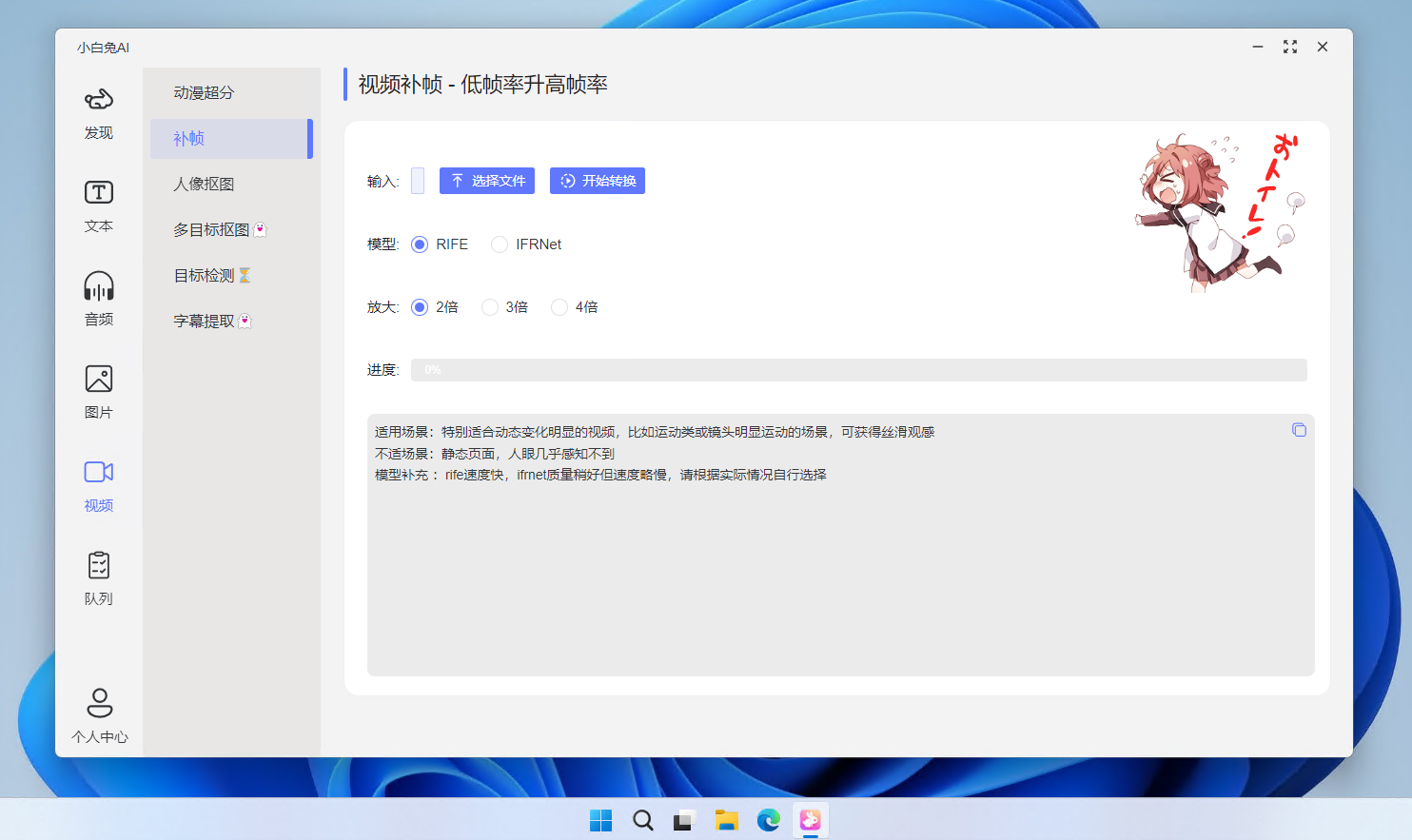
AI 人像修复
AI 人像修复嘛,就是利用 AI 模型,把因为失焦、低分辨率、高噪点等问题导致的模糊老照片 ,修复成更为清晰的人像图片。
其中效果、口碑都不错的开源项目有阿里家的 GPEN 和腾讯家的 GFPGAN,今天这个 Paper2gui 项目里的 AI 人像修复工具,封装的就是 GFPGAN。
具体操作就跟前面说的那样,有手就行, 「选择文件」找到待修复的图,然后知识兔点击「开始」,静等 1 秒,在原图目录下就会生成修复后的图片。
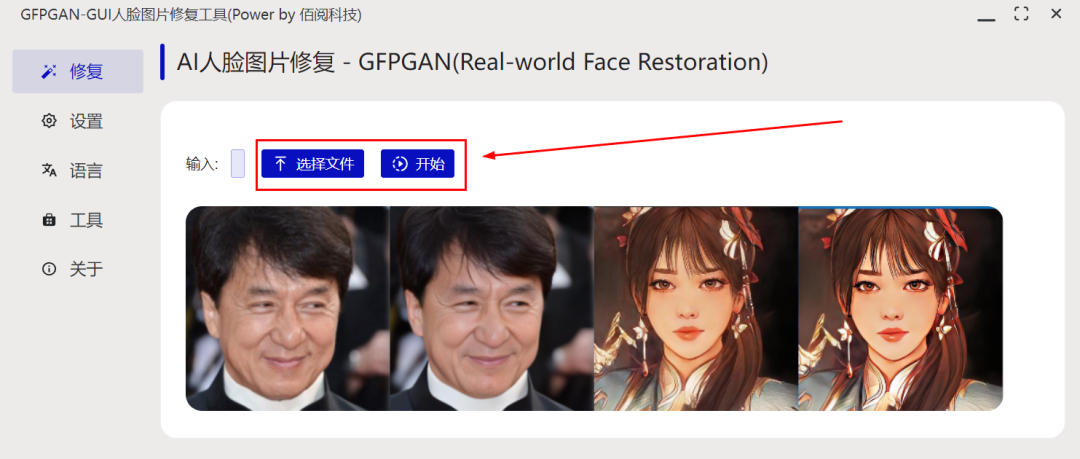
我们还是直接来看效果吧,左边为我从浏览器直接截的老照片,右边为修复出的效果图,有老太太:

老爷爷:

还有小女孩:

当然,也有这种略微有点翻车的,所以在测试时,最好用那种五官清晰的正面照。

不过据作者所说,目前受限于 ncnn 模型转换,这个工具只有 N × N 的矩形图片效果最好。
图片转漫画
去年 GitHub 上由武汉大学和湖北工业大学倒腾出来的 AnimeGAN 项目很火,它可以把人物图片通过 AI 模型转变成漫画人物,这是项目上给出的示例:

其实你在知乎、B 站上一搜,能找到不少教你把代码部署到本地,然后知识兔通过命令行调用生成的教程。
Paper2gui 的工具就很傻瓜操作了,和上面那个工具一样,可选项就一个「选择文件」,一个「开始」。
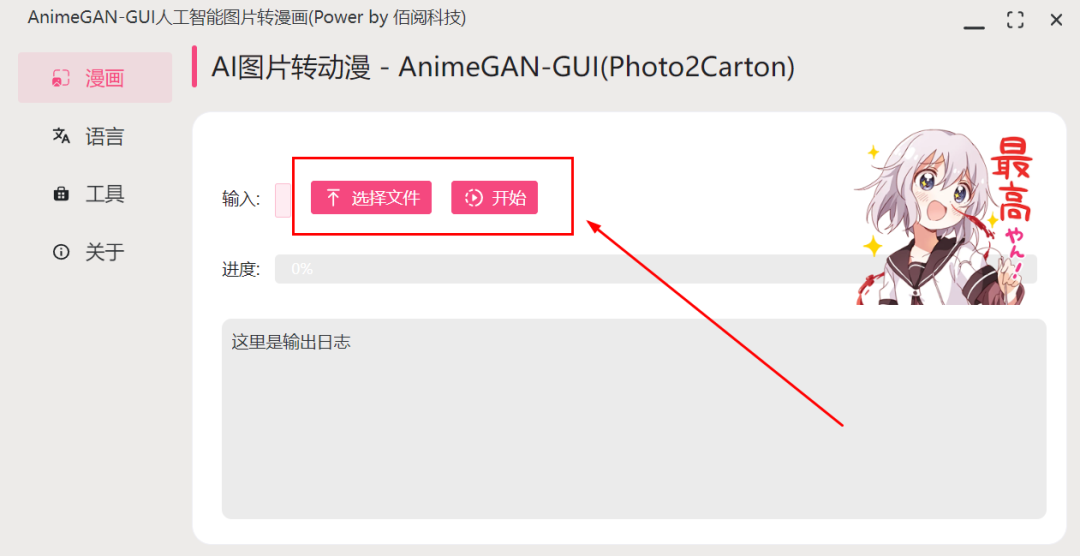
所以我们还是直接来看效果,比如 BlackPink 女团里的 Jennie:

比如国内的女星,杨颖和杨幂:


还有「此人不存在」这个网站上随机生成的人像:

我甚至还试了两张小动物,虽然不是人像,但同样非常有趣:


软件本身只有不到 9M 大小,如果知识兔大家想自己做个漫画风头像,不用再去找 App、网站了,这个小工具帮你轻松解决。
美中不足的是,和上面一样,测试时我发现只有 N × N 的矩形图片效果最好,不过对于头像来说矩形正合适。
视频4K放大、人像高清修复工具
所谓 AI 变高清其实就是 AI 无损放大,通过算法把低分辨率的图像映射生成一张高分辨率的图像,知识兔从而实现变高清的功能。
老牌的 waifu2x 模型,这两年正火的腾讯家的 Real-ESRGAN 效果都很不错,过去我们安利的工具也大多出自这两种模型。

而在 Paper2gui 里,直接把这些模型给包圆了,都有相对应的工具:
比如 Real-ESRGAN 的 4 倍放大,知识兔可以把 95KB 大小,217 × 217 分辨率的模糊图片,变成 942KB 大小,872 × 872 分辨率的清晰图片,强行拼图就成了下面这样:

当然,还有这种变高清的,这是原图:

这是 4 倍放大的高清图:

更厉害的是,Paper2gui 里的这些工具,是支持视频放大变高清的,不知道大家在 B 站、抖音上见没见过那种老视频、老 MV 的修复版片段,就是逐帧逐帧把图片变清晰后再合成,现在我们也能这么搞。
下面是测试效果:
视频的放大对硬件有不小的要求,处理起来会吃不少资源,虽然 Paper2gui 分享有内存模式,但老爷机还是慎用。。。

AI 视频抠像/人像抠图
抠图,一键去除背景,保留人像。抠图细节基本满意。

但 Paper2gui 中,分享有两个独立的 AI 视频抠像工具,操作同样小白。
我试了两个视频,给大家看看效果
处理后
可以看到,这些自动抠像后会帮你输出一个绿幕背景,后期你想再怎么折腾也就更方便了。
不过问题也有,视频抠图针对采访、座谈类效果更好。对于比如跳舞的小姐姐,当人物动作浮动偏大后,抠图效果就不理想了。
人工智能语音合成
比如 Paper2gui 的微软、抖音、阿里三家语音合成工具,像抖音这个,和剪映里的 AI 声一模一样,相信有小伙伴用的到。

测试抖音火山语音合成效果
各引擎使用效果对比
- 逼真度:微软 > 火山 > 阿里云
- 语言丰富度: 微软 > 火山 > 阿里云
- 中文丰富度: 火山 > 微软 > 阿里云
- 费用:微软 > 阿里云 > 火山
视频补帧
Paper2gui 里有两款视频补帧工具,所谓补帧,就是把视频重新分割为一张张图片,然后知识兔两张图片之间再利用 AI 算法重新生成一张中间图,合成后的视频看着就更流畅了。
这是原视频:

这是补帧后的新视频:

区别还是挺明显的,但问题是这玩意太吃硬件,硬件够的小伙伴可以去试试。
AI目标检测
还有一个 AI 自动识别的功能,知识兔可以识别人,识别物件,但好像需要自己添加模型,所以知道 YOLO 且想玩的,知识兔可以自己去了解一下。
写在最后
上面提到的每一个 Paper2gui 里 AI 工具,都是独立的可执行文件,体积小,操作简单,Paper2gui 这项目妥妥一个 AI 工具箱。
对哪个功能感兴趣,下载下来试试看,反正开箱即用,随用随走,哎这就很棒。
下载仅供下载体验和测试学习,不得商用和正当使用。