Robots元指令(有时称为“元标记”)是一段代码,为爬虫程序分享如何对网页内容进行爬网或索引的指令。虽然robots.txt文件指令为bots分享了如何对网站页面进行爬网的建议,但robots元指令分享了关于如何对页面内容进行爬网和索引的更为明确的指示。
有两种类型的robots元指令:一种是HTML页面的一部分(比如meta robots tag),另一种是web服务器作为HTTP头(比如x-robots-tag)发送的。相同的参数(即,元标记分享的爬行或索引指令,如上例中的“noindex”和“nofollow”)可用于元robots和x-robots-tag;不同的是这些参数如何与爬虫程序通信。

元指令向爬虫程序分享有关如何对在特定网页上找到的信息进行爬网和索引的指令。如果知识兔这些指令是由bot发现的,那么它们的参数将为爬虫索引行为分享强有力的建议。但与robots.txt文件一样,爬虫程序不必遵循您的元指令,因此可以肯定,某些恶意的web robots会忽略您的指令。
以下是搜索引擎爬虫在meta robots指令中使用时理解和遵循的参数。这些参数不区分大小写,但请注意,有些搜索引擎可能只遵循这些参数的一个子集,或者对某些指令的处理略有不同。
索引控制参数:
- Noindex:告诉搜索引擎不要为页面编制索引。
- Index:告诉搜索引擎为页面建立索引。请注意,您不需要添加此元标记;这是默认值。
- Follow:即使知识兔该页面未编制索引,爬网程序也应跟踪页面上的所有链接,并将所有者权益传递给链接的页面。
- Nofollow:告诉抓取工具不要关注页面上的任何链接或传递任何链接权益。
- Noimageindex:告诉爬虫程序不要索引页面上的任何图像。
- None:等同于同时使用noindex和nofollow标记。
- Noarchive:搜索引擎不应在SERP上显示指向此页面的缓存链接。
- Nocache:与noarchive相同,但仅由Internet Explorer和Firefox使用。
- Nosnippet:告诉搜索引擎不要在SERP上显示此页面的该片段(即元描述)。
- Noodyp / noydir [OBSOLETE]:禁止搜索引擎使用页面的DMOZ描述作为该页面的SERP代码段。但是,DMOZ已于2017年初退休,这使得该标签已过时。
- Unavailable_after:在特定日期之后,搜索引擎不应再对此页面编制索引。
robots元指令的类型
robots元指令主要有两种类型:robots元标签和x-robots-tag。知识兔可以在meta robots标记中使用的任何参数也可以在x-robots-tag中指定。
我们将在下面讨论meta robots和x-robots标签指令。
meta robots标签
meta robots标记(通常称为“ meta robots”或俗称“ robots标记”)是网页HTML代码的一部分,并显示为网页
部分中的代码元素:
代码示例:
尽管常规标签是标准标签,但您也可以通过将“robots”替换为特定用户代理的名称来向特定的爬虫程序分享指令。例如,要将指令专门针对Googlebot,知识兔可以使用以下代码:
是否要在页面上使用多个指令?只要它们针对同一个“ robots”(用户代理),多个指令就可以包含在一个meta指令中–只需用逗号将它们分开即可。这是一个例子:
此标记将告诉robots不要索引页面上的任何图像、跟随任何链接或在SERP上显示页面的片段。
如果知识兔您对不同的搜索用户代理使用不同的meta robots标签指令,则需要为每个robots使用单独的标签。
X-robots-tag
尽管meta robots标签允许您在页面级别控制索引编制行为,但x-robots-tag可以作为HTTP标头的一部分包含在内,知识兔以控制整个页面以及页面的特定元素的编制索引。
虽然您可以使用x-robots-tag来执行与meta robots相同的所有索引指令,但x-robots-tag指令分享了meta robots标记所没有的更大的灵活性和功能。特别是,x-robots-tag允许使用正则表达式,在非HTML文件上执行抓取指令以及在全局级别应用参数。
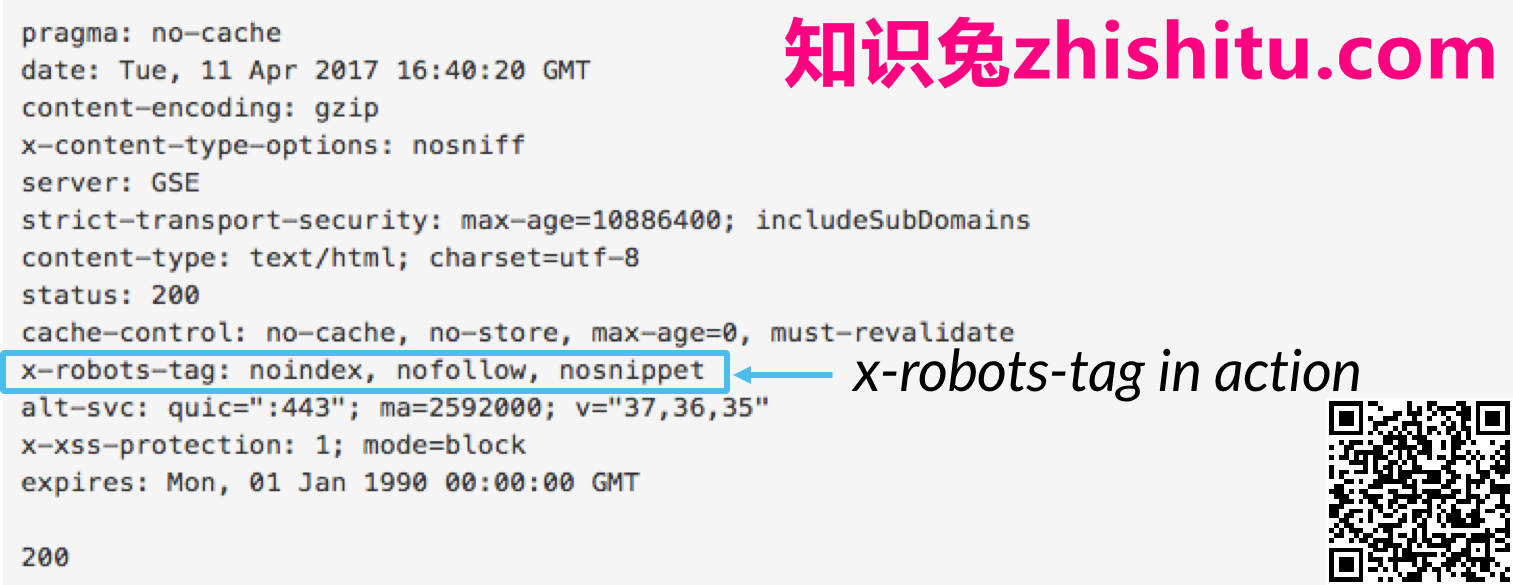
要使用x-robots-tag,您需要访问网站的header.php、.htaccess或服务器访问文件。然后知识兔,添加特定服务器配置的x-robots-tag标记,知识兔包括任何参数。本文分享了一些很好的例子,说明如果知识兔使用这三种配置中的任何一种,那么x-robots-tag标记是什么样子的。
以下是一些使用x-robots-tag的用例:
- 控制非HTML内容(如Flash或视频)的索引编制
- 阻止页面的特定元素(例如图像或视频)的索引编制,但不阻止整个页面本身的索引编制
- 如果知识兔您无权访问页面的HTML(特别是部分),或者您的网站使用无法更改的全局header,则控制索引编制
- 为是否应为页面建立索引添加规则(例如,如果知识兔用户发表了20次以上的评论,则为其个人资料页面建立索引)
使用robots元指令的SEO最佳实践
- 爬网URL时会发现所有元指令(robots或其他)。这意味着,如果知识兔robots.txt文件禁止抓取该URL,则该页面上的任何meta指令(在HTML或HTTP标头中)都不会被看到,并且知识兔实际上将被忽略。
- 在大多数情况下,应使用带有参数“ noindex,follow”的meta robots标记作为一种限制爬网或索引的方法,而不是使用robots.txt文件不允许。
- 重要的是要注意,恶意爬网程序可能会完全忽略robots元指令,因此,此协议不能分享良好的安全性机制。如果知识兔您有不想公开搜索的私人信息,请选择一种更安全的方法,例如密码保护,知识兔以防止访问者查看机密页面。
- 您无需在同一页面上同时使用meta robots和x-robots-tag-这样做将是多余的。
[ppwp passwords=”zhishitu.cn”]
下载体验
下载链接:
如果知识兔链接失效了,请找客服哈
[/ppwp]
发表回复